From Basic to Agentic RAG: Architecture Strategies for AI-Powered Service
.png)
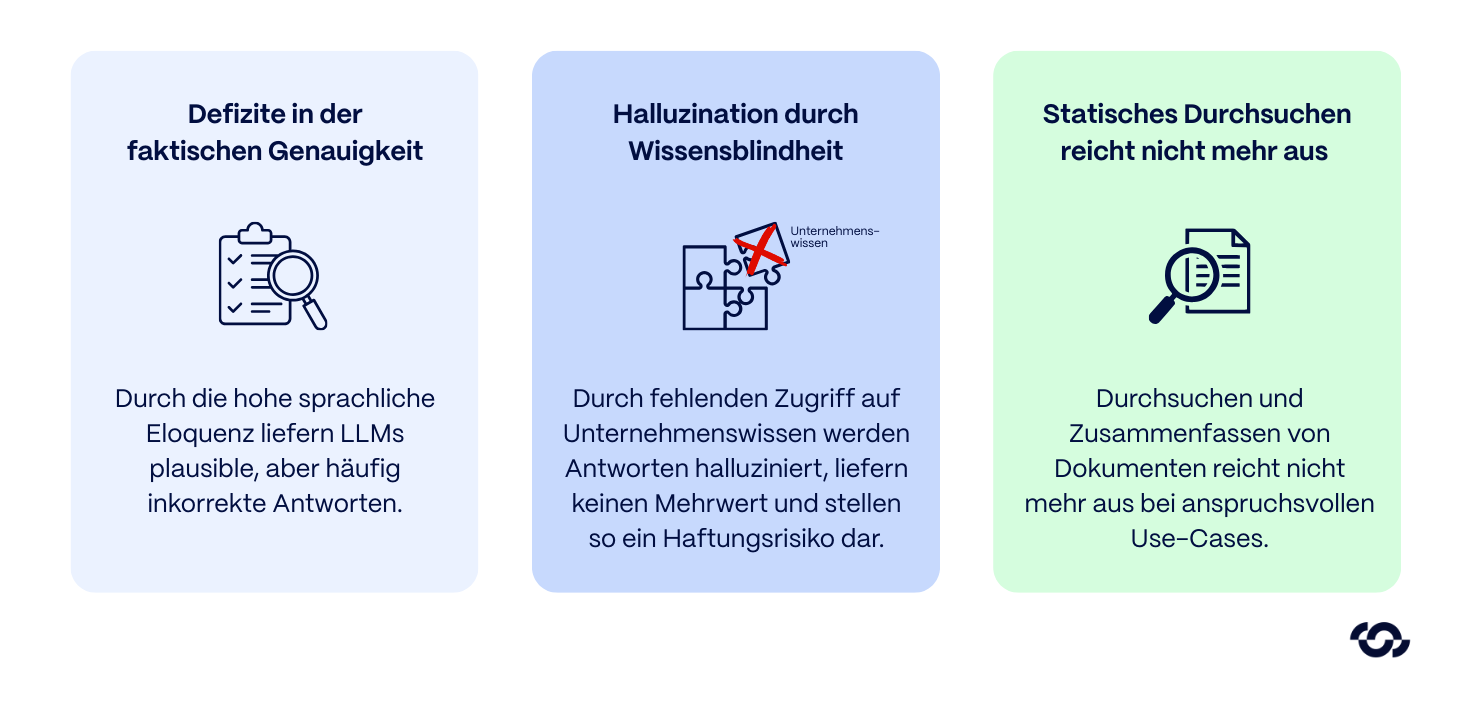
When automating complex service processes, a central bottleneck of early AI initiatives quickly became apparent: Language models (LLMs) may have a high level of linguistic eloquence, but lack factual accuracy. They tend to hallucinate plausible but incorrect answers and operate without access to proprietary, dynamically changing corporate knowledge.
In the context of technical support scenarios, this represents a significant risk. A chatbot that freely invents maintenance intervals or misquotes safety regulations does not offer any added value, but represents a direct liability risk.
Retrieval Augmented Generation (RAG) has fundamentally changed the status quo by enabling source-based AI answers based on proprietary data.
But what was still considered a technical breakthrough in 2023 now only marks the start. Statically searching and summarizing documents is often no longer sufficient for demanding use cases.
The topic of Agentic RAG is currently dominating the discourse — systems that are designed to solve problems autonomously instead of simply retrieving information. However, the question is: Is this approach the economically and technically sensible solution for every application?
Levels of maturity of RAG architectures
RAG is not a monolithic standard. Approaches that were recently considered innovative are now often legacy concepts. In order to allocate budgets efficiently and avoid technical debts, a clear differentiation of the levels of maturity and their specific areas of application is necessary.
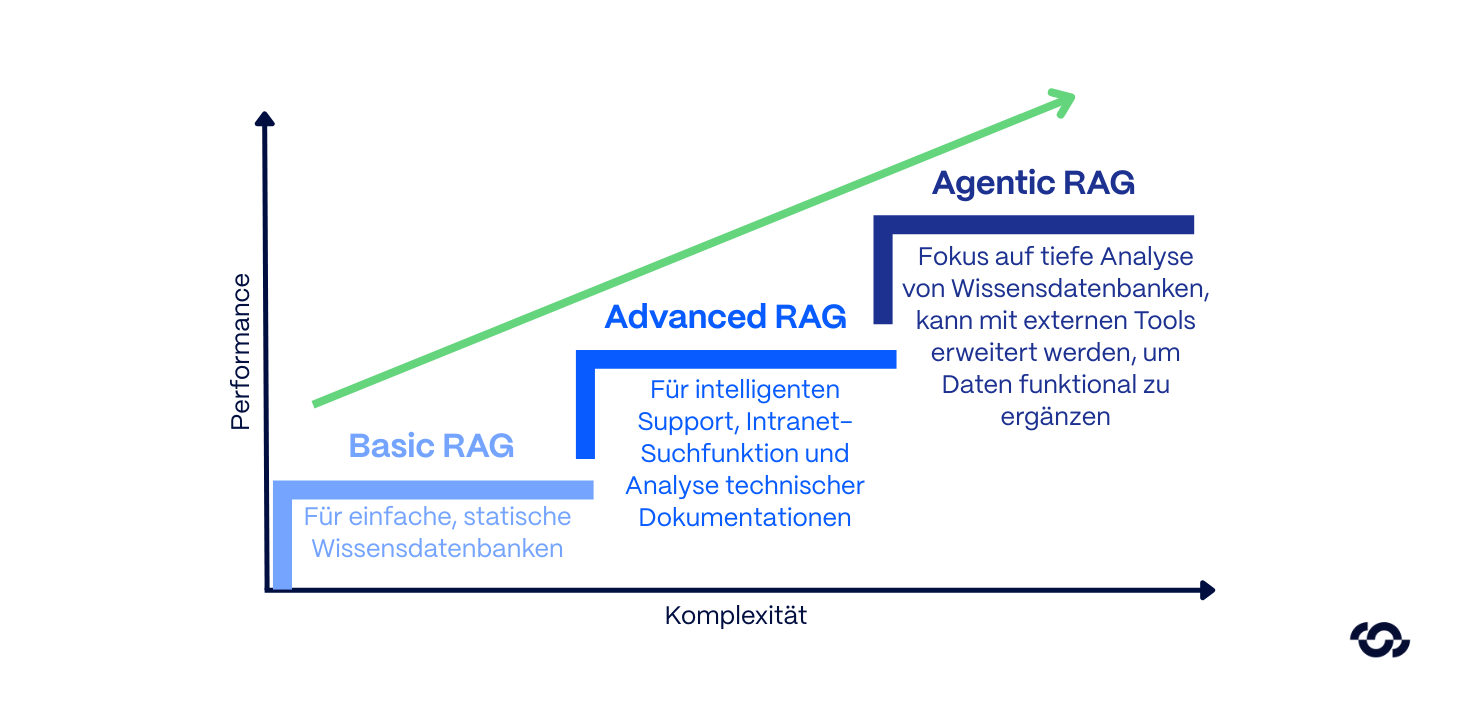
1. Basic RAG
The first stage of evolution, often also classified as Naive RAG, represents the original standard approach. Documents are segmented into static text blocks (chunks), vectorized and persisted in a vector database.
The process follows the “retrieve-then-generate” scheme. In response to a user request, the system performs a similarity search, extracts the most relevant text fragments into the context of the LLM and generates an answer from them.
Technical limitations:
- This approach operates without nuanced understanding. He often suffers from semantic fragmentation when rigid chunking cuts off essential information.
- In addition, the “lost in the middle” phenomenon occurs in extensive contexts: The language model neglects relevant details when they are placed in the middle of an overloaded context window.
- Even when it comes to exact identifiers, pure vector search reaches its limits (e.g. differentiation between item number “XJ-900” and “XJ-900-B”), as it is optimized for semantic proximity and not for exact correspondence.
Area of use: Primarily suitable for initial proof-of-concepts (PoC) or simple, static knowledge databases. Basic RAG is now considered technically obsolete for business-critical enterprise applications.
2nd Advanced RAG
In the second stage, the linear process is significantly optimized through intelligent pre- & post-retrieval mechanisms. The goal is maximum relevance instead of mere mass of hits.
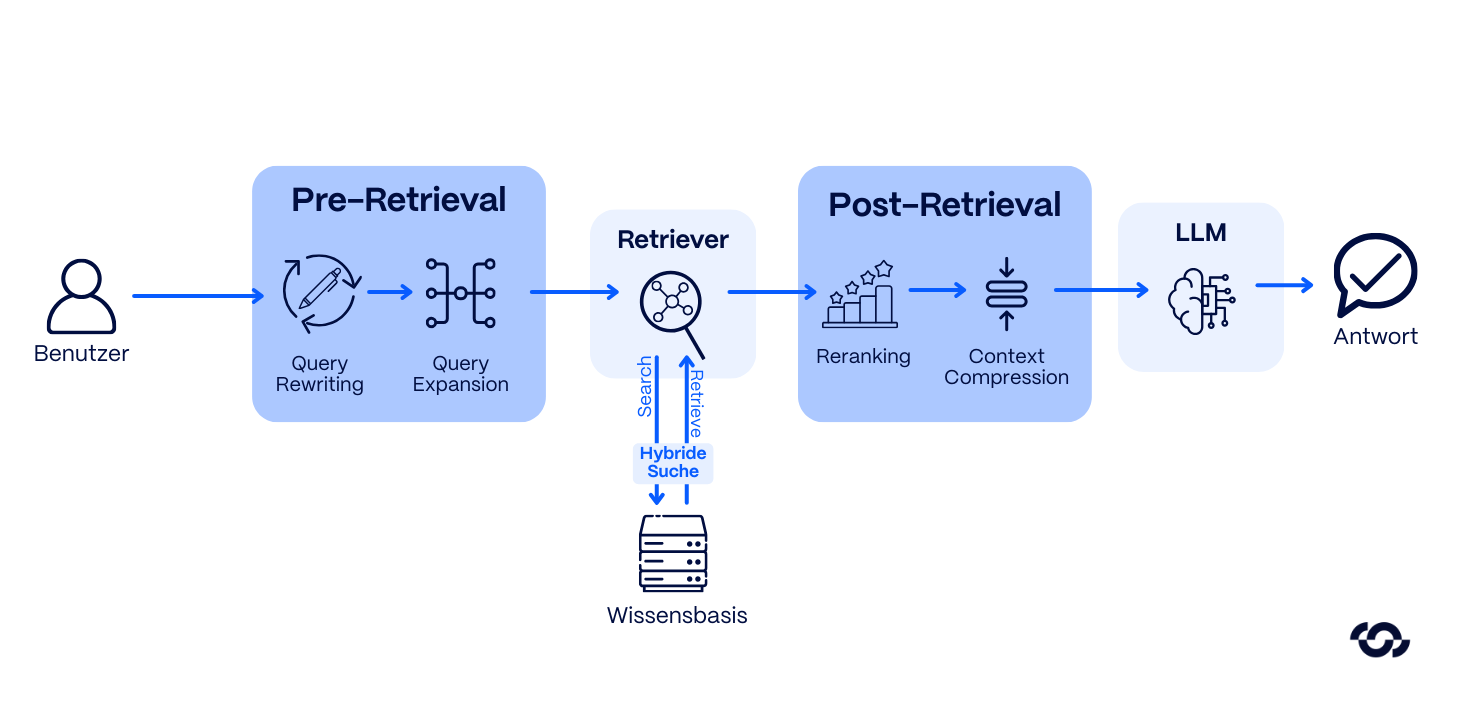
- Pre-Retrieval (Query Transformation): The system does not process the user question directly, but reformulates or expands it (Query Expansion) to cover synonyms and subject-specific jargon.
- Hybrid search: Here, lexical search (sparse retrieval via BM25 for exact hits) and semantic vector search (dense retrieval for the content context) are combined.
- Post-retrieval (reranking): In a second step, a specialized model validates the results found for their actual usefulness and filters out irrelevant noise before the data is transferred to the LLM.
These filtering mechanisms can drastically reduce the risk of hallucinations. For applications such as intelligent support, intranet search functions and analysis of technical documentation, this is currently the technological sweet spot.
3rd Agentic RAG
At this stage, the change from a pure search engine to a dynamic system with reasoning takes place. The LLM orchestrates the process and actively interacts with the documents instead of simply extracting text.
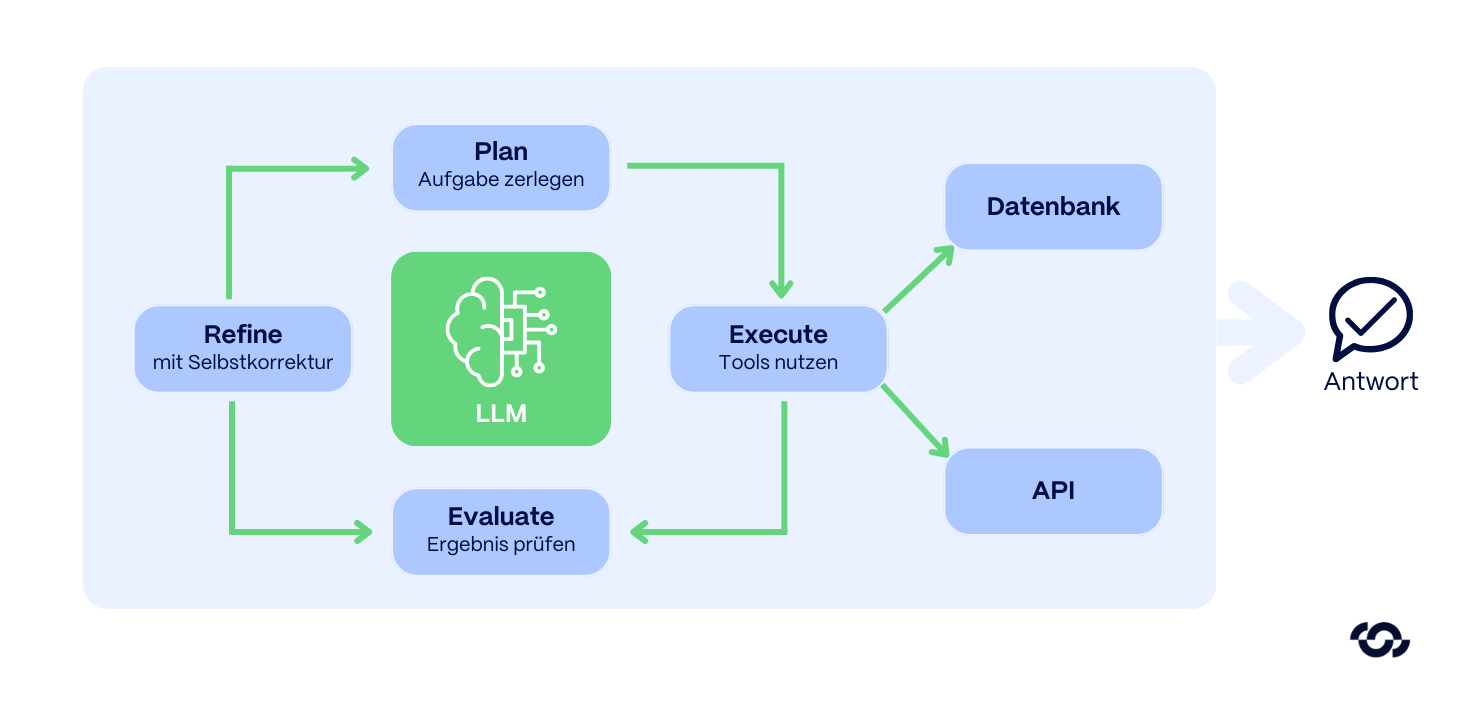
Instead of a linear query, the system uses iterative loops. The LLM acts as an orchestrator and creates a solution plan:
- Query Decomposition: Breaking down a complex question into logical subtasks.
- Multi-hop retrieval: Targeted execution of several search queries at different points in the document body.
- Evaluation: The system checks the interim result (“Is the information from chapter 3 sufficient? No, verification of the cross-reference in the annex is required. ”).
- Self-Correction: If a dead end is reached, the agent corrects itself and finally synthesizes the fragments into a precise answer.
Extension (Tool Use): Although the focus is on deep analysis of knowledge databases, this architecture can be equipped with external tools (such as API access) to functionally complement data.
Limitations: This iterative analysis (reasoning) is resource-intensive. Thanks to the feedback loops, Agentic RAG has a noticeably higher latency than its predecessors. This approach is often over-engineering for simple information queries, but there is no alternative for complex analytical tasks.
Excursus: Graph RAG
Graph RAG is not just another level, but a fundamentally different method of data structuring. While classic vector RAGs primarily search for textual similarities, they often fail due to the global context when logically related information is scattered across various documents.
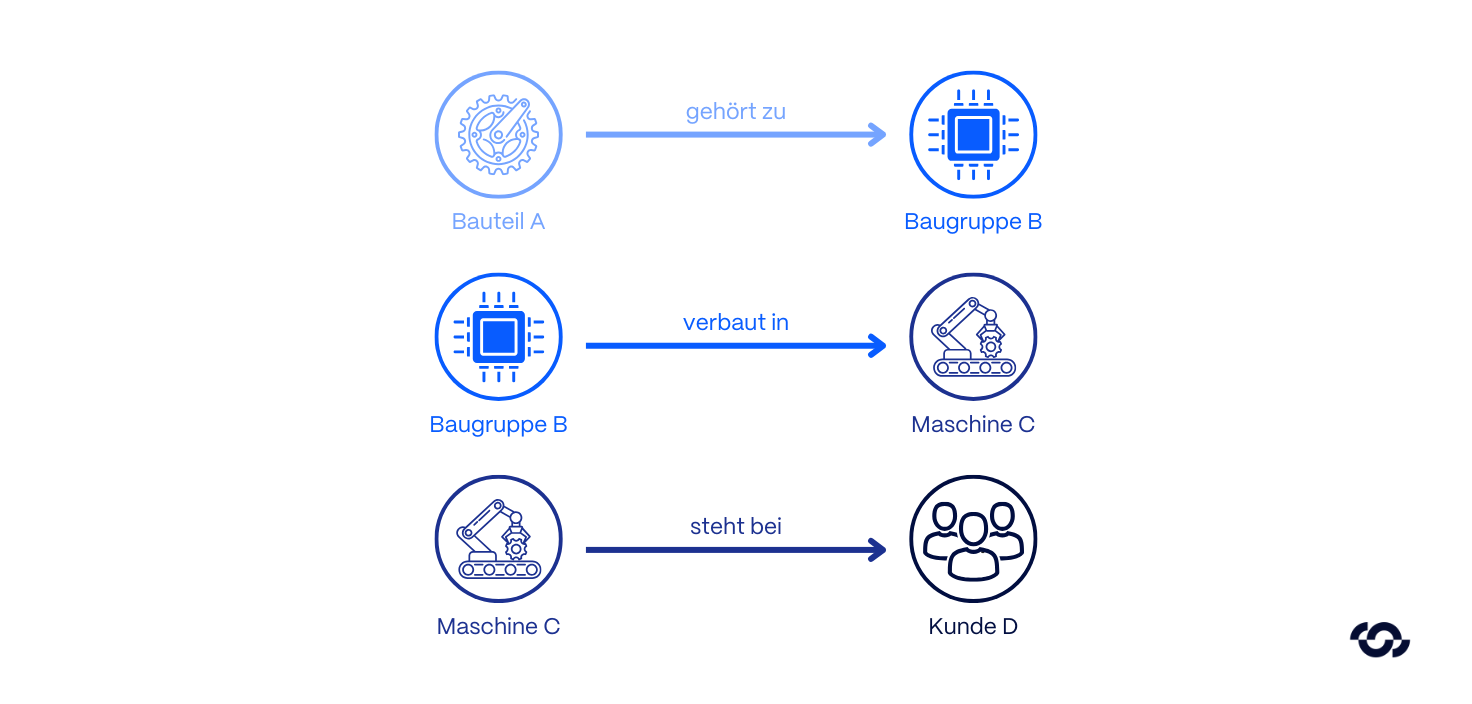
Here, the architecture switches from statistical probabilities to explicit structures.
- How it works: Data is not stored as isolated chunks of text, but in a Knowledge Graphtransferred. The system extracts entities (nodes) and their relationships (edges) and explicitly maps semantic connections.
- The strategic advantage: The system can draw logical conclusions across multiple document boundaries to identify complex causalities that remain hidden from a pure vector search.
- example: A vector search identifies documents relating to “supplier X”. Graph RAG answers the question: “What are the implications of the supplier X failure for all product lines in Asia? ”by traversing the dependencies (edges) in the graph.
- Area of use: Ideal for scenarios where the relationship between data points is more critical than the data point itself — for example in supply chain management (risk analysis), R&D (linking study results) or complex compliance checks.
Implementation challenges
The transformation from simple chatbots to integrated RAG architectures is not just an IT upgrade, but requires a strategic realignment of information processing. Successful implementations require consistent preparation of the data landscape, interfaces, and governance processes.
Data availability and quality
Even the most powerful models cannot compensate for fundamental deficiencies in the database (garbage in, garbage out). The output quality is directly correlated with the structuring of the information being fed in.
- Processing unstructured data: Formats such as PDFs or complex tables are often difficult to interpret by machine. Without robust ETL (Extract, Transform, Load) pipelines that precisely parse layouts, retrieval performance drops significantly.
- Metadata Strategy: Isolated documents often lack context. For effective filtering (e.g. after versioning), strict metadata collection is essential even during ingestion.
- Resolution of data silos: Critical business knowledge is often fragmented in legacy systems without modern APIs. The technical consolidation of these heterogeneous sources is often the biggest cost driver.
Latency and cost structure
There is a direct conflict of objectives between response quality and system performance. It is important to balance business value against operating costs (OpEx).
- latency: While Basic RAG answers almost in real time, the inference times add up with Agentic RAG. Every reasoning step and tool call increases latency. Response times of 10 to 30 seconds are technically necessary for deep analyses and require adapted expectation management.
- costs: Complex RAG pipelines multiply token consumption per request. Before scaling, a detailed profitability calculation is necessary to ensure that the higher operating costs are justified by the qualitative added value.
Data Sovereignty and Governance
The integration of AI into corporate data places high demands on compliance. RAG systems must not undermine existing security architectures.
- Authorization management: The system must ensure that users only access information via chat that they are authorized for in the source system (e.g. SharePoint). These access control lists must be replicated into the vector database and enforced with every query.
- Compliance & Data Residency: The choice between local models (on-premise/private cloud) and external providers (e.g. Azure OpenAI) is primarily a legal decision that must finally clarify data protection issues during the architecture phase.
Best practices: use cases
In order to make the architectural differences tangible, we compare two typical business requirements. This shows why a “one size fits all” approach at RAG is not effective.

Use case 1: Advanced RAG in technical field service
The scenario: Under time pressure, a service technician needs the exact specification of an error code (e.g. “E-404-X”) and the corresponding repair instructions before a system is shut down.
The technical solution: Precision is a priority here. The system uses a Advanced RAG Pipeline:
- Hybrid search: The lexical search ensures that exactly the specific error code is found, while the vector search provides the thematic context.
- Reranking: A downstream model filters irrelevant hits (e.g. instructions from outdated series) and prioritizes the correct service bulletin.
Architecture fit: Advanced RAG The focus is on the rapid, hallucination-free retrieval of statistical knowledge from extensive documentation. An agent would be unnecessarily complex here.
Use case 2: Agentic RAG with tool use in order management
The scenario: In the self-service portal, a customer asks: “Where is my order 12345-6? If it has not yet been shipped, please change the delivery address to our branch in Munich. ”
The technical solution: This request requires access to real-time data and decision logic. A Agentic RAG System takes over the orchestration:
- Decomposition & tooling: The agent identifies two subtasks (check status, change address).
- Reasoning Loop:
- Step 1: Status retrieval via ERP API. Result: “In process.”
- Logic check: “Is change allowed? Yes, because status ≠ Sent. ”
- Step 2: Retrieve valid delivery addresses from CRM (validation: Does “Munich” exist?).
- Step 3: Execute the write operation (update address) in the ERP system.
- Step 1: Status retrieval via ERP API. Result: “In process.”
- Synthesis: Generation of the response, including a new delivery forecast.
Architecture fit: Agentic RAG. This is not just about reproducing information, but about action. The system must handle dynamic processes, operate live interfaces and apply multi-level business logic autonomously.
Implementation roadmap
- Use case classification: Analyze the problem precisely. Is an intelligent search sufficient (Advanced RAG) or is an active problem solver needed (Agentic RAG)?
- Data & API audit: Understand your data structure Graph RAG, for example, requires clearly defined entities and relationships, whereas Agentic RAG also requires your APIs to be highly relevant.
- Piloting: Start with Advanced RAG as a solid basis. As soon as search and reranking perform reliably, the system can be expanded modularly.
- Integration & Guardrails: Implement strict access controls and limits to ensure data security.
conclusion
RAG has developed from a simple search extension to a versatile architectural component for semi-autonomous AI systems - especially wherever AI should not only answer, but also provide reliable reasons, work comprehensibly and ultimately deliver actionable results. The key point: Not every RAG pipeline fits every use case. Whoever builds “too small” gets poor quality — whoever builds “too big” pays complexity, operating costs and time-to-value.
While Basic RAG is inadequate for complex processes, Advanced RAG significantly increases hit quality through query transformation, hybrid search and reranking. Graph RAG uses knowledge graphs to resolve complex, distributed relationships and further reduce hallucinations. Agentic RAG is at the forefront of development: Here, the LLM plans independently, breaks down tasks and delivers concrete, actionable results through iterative processes.
Companies are well advised to analyse their use cases in detail and to choose the technologically appropriate level instead of following trends. Are you unsure which RAG level provides the best ROI for your specific scenario or how to optimally prepare your database?
As a strategic partner, we are happy to assist you in evaluating your use cases and selecting the appropriate technology components.
Share this article
%20(3000%20x%202000%20px).png)

.png)