.png)
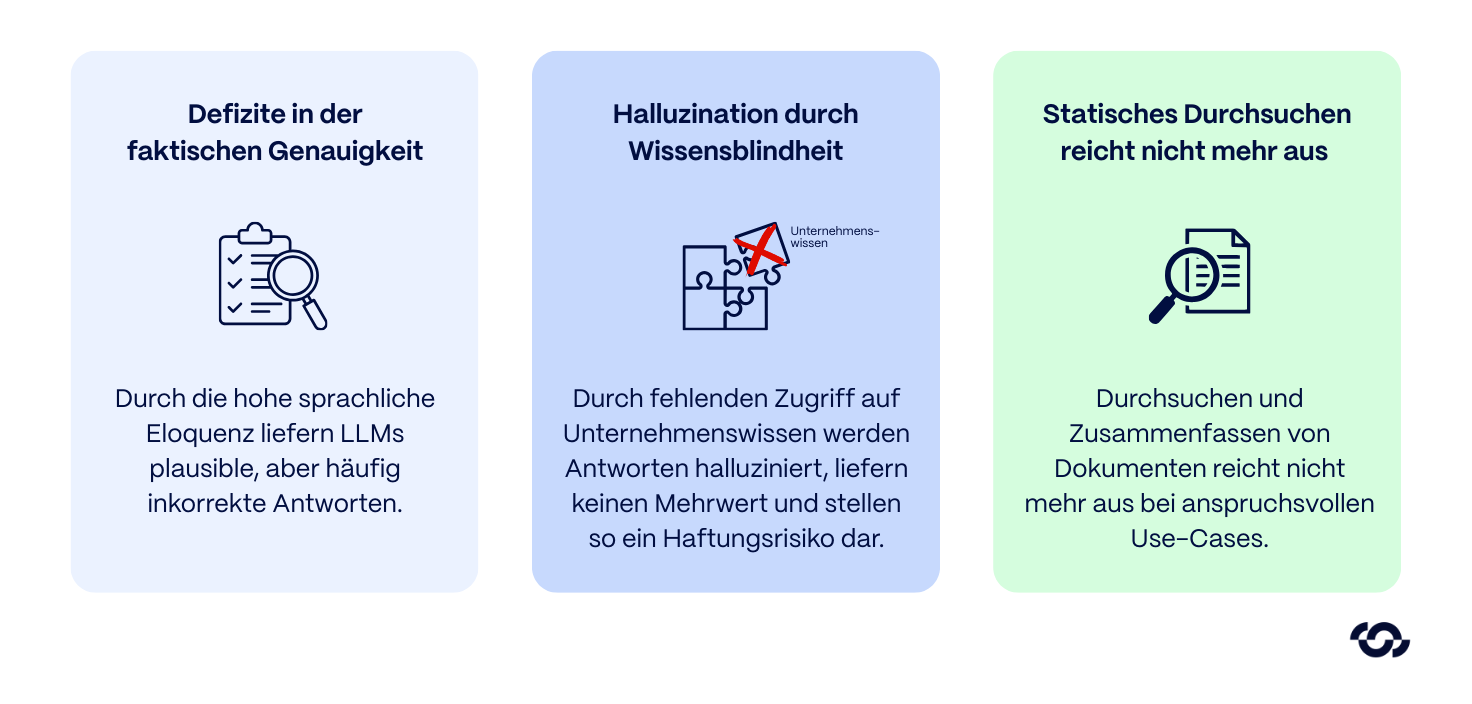
Bei der Automatisierung komplexer Serviceprozesse zeigte sich schnell ein zentraler Engpass früher KI-Initiativen: Sprachmodelle (LLMs) besitzen zwar eine hohe sprachliche Eloquenz, weisen jedoch Defizite in der faktischen Genauigkeit auf. Sie tendieren dazu, plausible, aber inkorrekte Antworten zu halluzinieren und operieren ohne Zugriff auf proprietäres, sich dynamisch änderndes Unternehmenswissen.
Im Kontext technischer Support-Szenarien stellt dies ein signifikantes Risiko dar. Ein Chatbot, der Wartungsintervalle frei erfindet oder Sicherheitsvorschriften falsch zitiert, bietet keinen Mehrwert, sondern stellt ein direktes Haftungsrisiko dar.
Retrieval Augmented Generation (RAG) hat den Status quo fundamental verändert, indem es quellenbasierte KI-Antworten auf Basis eigener Daten ermöglicht.
Doch was 2023 noch als technischer Durchbruch galt, markiert heute lediglich den Einstieg. Das statische Durchsuchen und Zusammenfassen von Dokumenten reicht für anspruchsvolle Use-Cases oft nicht mehr aus.
Aktuell dominiert das Thema Agentic RAG den Diskurs – Systeme, die darauf ausgelegt sind, Probleme autonom zu lösen, statt lediglich Informationen abzurufen. Es stellt sich jedoch die Frage: Ist dieser Ansatz für jeden Anwendungsfall die ökonomisch und technisch sinnvolle Lösung?
Reifegrade der RAG-Architekturen
RAG ist kein monolithischer Standard. Ansätze, die vor kurzem noch als innovativ galten, sind heute oft bereits Legacy-Konzepte. Um Budgets effizient zu allokieren und technische Schulden zu vermeiden, ist eine klare Differenzierung der Reifegrade und ihrer spezifischen Einsatzgebiete notwendig.
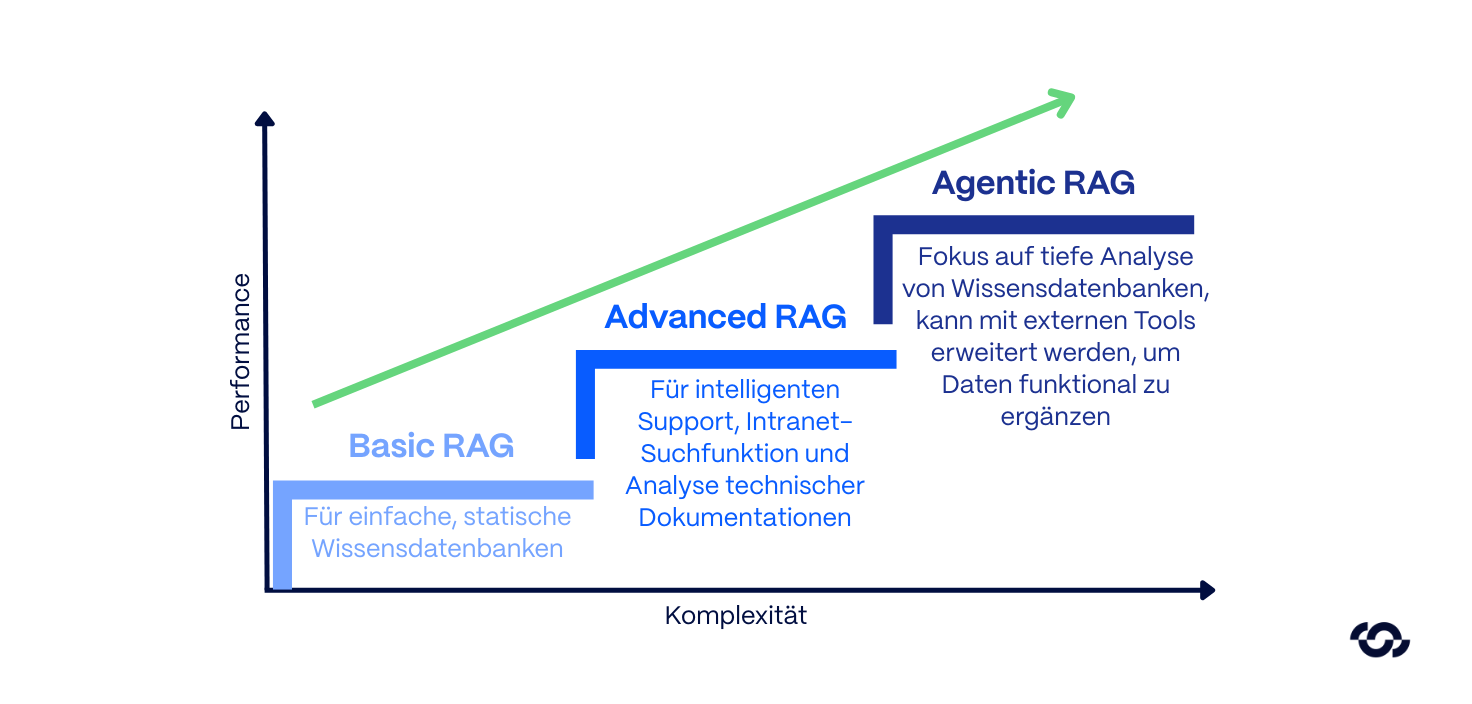
1. Basic RAG
Die erste Evolutionsstufe, oft auch als Naive RAG klassifiziert, bildet den ursprünglichen Standardansatz ab. Dokumente werden hierbei in statische Textblöcke (Chunks) segmentiert, vektorisiert und in einer Vektordatenbank persistiert.
Der Prozess folgt dem Schema „Retrieve-then-Generate“. Auf eine Nutzeranfrage hin führt das System eine Ähnlichkeitssuche durch, extrahiert die relevantesten Textfragmente in den Kontext des LLMs und generiert daraus eine Antwort.
Technische Limitierungen:
- Dieser Ansatz operiert ohne nuanciertes Verständnis. Er leidet häufig unter Semantic Fragmentation, wenn starres Chunking essenzielle Informationen abschneidet.
- Zudem tritt bei umfangreichen Kontexten das „Lost in the Middle“-Phänomen auf: Das Sprachmodell vernachlässigt relevante Details, wenn diese in der Mitte eines überladenen Kontextfensters platziert sind.
- Auch bei exakten Identifikatoren stößt die reine Vektorsuche an ihre Grenzen (z. B. Unterscheidung Artikelnummer „XJ-900“ vs. „XJ-900-B“), da sie auf semantische Nähe und nicht auf exakte Übereinstimmung optimiert ist.
Einsatzgebiet: Primär geeignet für initiale Proof-of-Concepts (PoC) oder einfache, statische Wissensdatenbanken. Für geschäftskritische Enterprise-Anwendungen gilt Basic RAG mittlerweile als technisch überholt.
2. Advanced RAG
In der zweiten Stufe wird der lineare Prozess durch intelligente Pre- & Post-Retrieval-Mechanismen signifikant optimiert. Das Ziel ist maximale Relevanz statt bloßer Masse an Treffern.

- Pre-Retrieval (Query Transformation): Das System verarbeitet die Nutzerfrage nicht direkt, sondern formuliert sie um oder erweitert sie (Query Expansion), um Synonyme und fachspezifischen Jargon abzudecken.
- Hybrid Search: Hier werden lexikalische Suche (Sparse Retrieval via BM25 für exakte Treffer) und semantische Vektorsuche (Dense Retrieval für den inhaltlichen Kontext) kombiniert.
- Post-Retrieval (Reranking): Ein spezialisiertes Modell validiert die gefundenen Treffer in einem zweiten Schritt auf ihre tatsächliche Nützlichkeit und filtert irrelevantes Rauschen (Noise) heraus, bevor die Daten an das LLM übergeben werden.
Durch diese Filtermechanismen lässt sich das Halluzinationsrisiko drastisch reduzieren. Für Anwendungen wie intelligenten Support, Intranet-Suchfunktionen und die Analyse technischer Dokumentationen stellt dies aktuell den technologischen Sweet Spot dar.
3. Agentic RAG
Auf dieser Stufe vollzieht sich der Wandel von einer reinen Suchmaschine zu einem dynamischen System mit Reasoning. Das LLM übernimmt die Orchestrierung des Ablaufs und interagiert aktiv mit den Dokumenten, statt lediglich Text zu extrahieren.

Anstelle einer linearen Abfrage nutzt das System iterative Schleifen (Loops). Das LLM agiert als Orchestrator und erstellt einen Lösungsplan:
- Query Decomposition: Zerlegung einer komplexen Fragestellung in logische Teilaufgaben.
- Multi-Hop Retrieval: Gezielte Durchführung mehrerer Suchabfragen an unterschiedlichen Stellen im Dokumentenkorpus.
- Evaluation: Das System prüft das Zwischenergebnis („Reicht die Information aus Kapitel 3? Nein, Prüfung des Querverweises im Anhang erforderlich.“).
- Self-Correction: Falls eine Sackgasse erreicht wird, korrigiert sich der Agent selbst und synthetisiert die Fragmente am Ende zu einer präzisen Antwort.
Erweiterung (Tool Use): Obwohl der Fokus auf der tiefen Analyse von Wissensdatenbanken liegt, kann diese Architektur mit externen Tools (z. B. API-Zugriffen) ausgestattet werden, um Daten funktional zu ergänzen.
Limitierungen: Diese iterative Analyse (Reasoning) ist ressourcenintensiv. Agentic RAG weist durch die Feedback-Loops eine spürbar höhere Latenz auf als seine Vorgänger. Für simple Informationsabfragen ist dieser Ansatz oft Over-Engineering, für komplexe analytische Aufgaben jedoch alternativlos.
Exkurs: Graph RAG
Graph RAG ist weniger eine weitere Stufe, sondern eine fundamental andere Methode der Datenstrukturierung. Während klassische Vektor-RAGs primär nach textlicher Ähnlichkeit suchen, scheitern sie oft am globalen Kontext, wenn logisch zusammengehörige Informationen über diverse Dokumente verstreut sind.
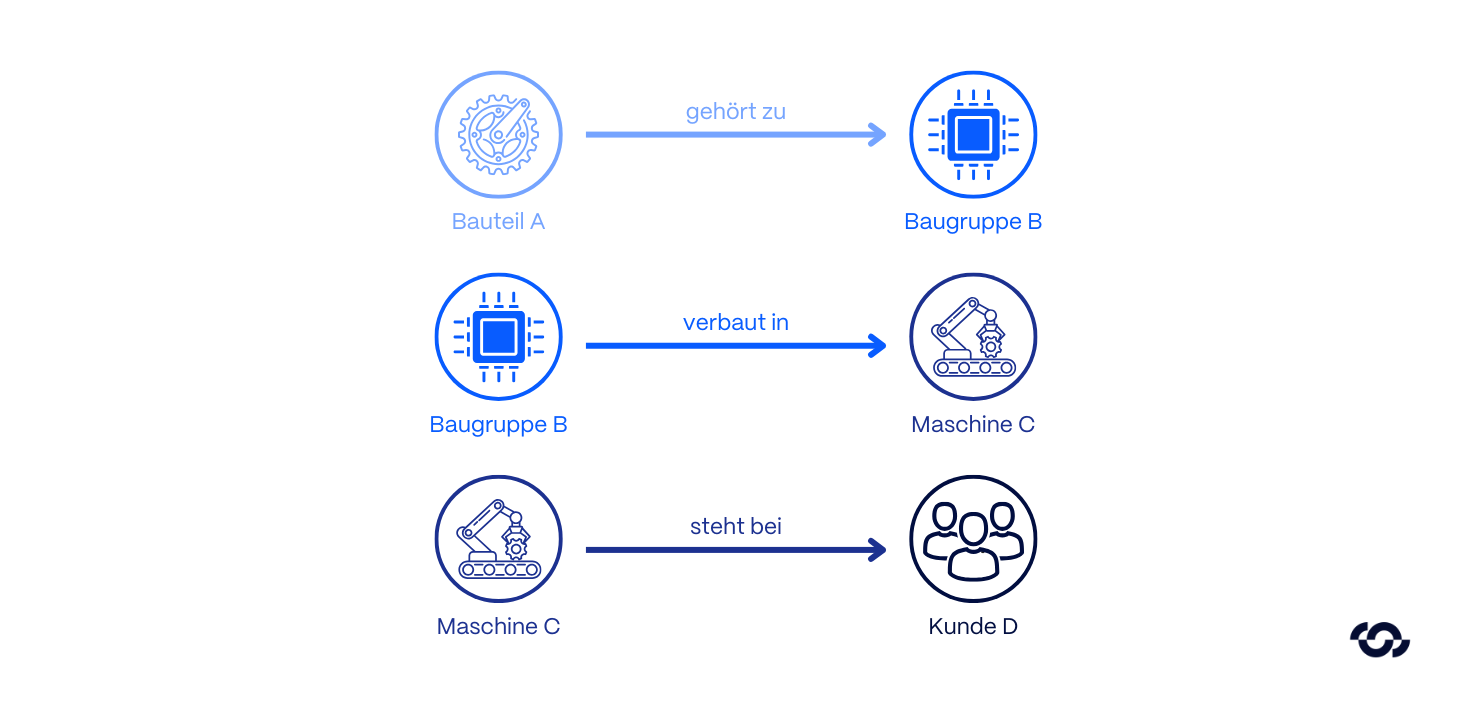
Hier wechselt die Architektur von statistischen Wahrscheinlichkeiten zu expliziten Strukturen.
- Funktionsweise: Daten werden nicht als isolierte Text-Chunks abgelegt, sondern in einen Knowledge Graph überführt. Das System extrahiert Entitäten (Knoten) und deren Beziehungen (Kanten) und bildet semantische Verbindungen explizit ab.
- Der strategische Vorteil: Das System kann logische Schlüsse über mehrere Dokumentengrenzen hinweg ziehen, um komplexe Kausalitäten zu erkennen, die einer reinen Vektorsuche verborgen bleiben.
- Beispiel:
- Eine Vektorsuche identifiziert Dokumente zum „Lieferanten X“.
- Graph RAG beantwortet die Frage: „Welche Implikationen hat der Ausfall von Lieferant X auf alle Produktlinien in Asien?“, indem es die Abhängigkeiten (Edges) im Graphen traversiert.
- Beispiel:
- Einsatzgebiet: Ideal für Szenarien, in denen die Beziehung zwischen Datenpunkten kritischer ist als der Datenpunkt selbst – etwa im Supply Chain Management (Risikoanalyse), R&D (Verknüpfung von Studienergebnissen) oder bei komplexen Compliance-Prüfungen.
Herausforderungen bei der Implementierung
Die Transformation von einfachen Chatbots hin zu integrierten RAG-Architekturen ist kein reines IT-Upgrade, sondern erfordert eine strategische Neuausrichtung der Informationsverarbeitung. Erfolgreiche Implementierungen setzen eine konsequente Vorbereitung der Datenlandschaft, Schnittstellen und Governance-Prozesse voraus.
Datenverfügbarkeit und Qualität
Selbst leistungsfähigste Modelle können fundamentale Defizite in der Datenbasis nicht kompensieren (Garbage In, Garbage Out). Die Output-Qualität korreliert direkt mit der Strukturierung der eingespeisten Informationen.
- Verarbeitung unstrukturierter Daten: Formate wie PDFs oder komplexe Tabellen sind maschinell oft schwer interpretierbar. Ohne robuste ETL-Pipelines (Extract, Transform, Load), die Layouts präzise parsen, sinkt die Retrieval-Performance signifikant.
- Metadaten-Strategie: Isolierten Dokumenten fehlt oft der Kontext. Für effektives Filtering (z. B. nach Versionierung) ist eine strikte Metadaten-Erfassung bereits während der Ingestion essenziell.
- Auflösung von Datensilos: Kritisches Unternehmenswissen liegt oft fragmentiert in Legacy-Systemen ohne moderne APIs vor. Die technische Konsolidierung dieser heterogenen Quellen ist häufig der größte Aufwandstreiber.
Latenz und Kostenstruktur
Zwischen Antwortqualität und Systemperformance besteht ein direkter Zielkonflikt. Es gilt, den Business Value gegen die Betriebskosten (OpEx) abzuwägen.
- Latenz: Während Basic RAG nahezu in Echtzeit antwortet, summieren sich bei Agentic RAG die Inferenzzeiten. Jeder Reasoning-Schritt und jeder Tool-Call erhöht die Latenz. Antwortzeiten von 10 bis 30 Sekunden sind bei tiefen Analysen technisch bedingt und erfordern ein angepasstes Erwartungsmanagement.
- Kosten: Komplexe RAG-Pipelines vervielfachen den Token-Verbrauch pro Request. Vor der Skalierung ist eine detaillierte Wirtschaftlichkeitsberechnung notwendig, um sicherzustellen, dass die höheren Betriebskosten durch den qualitativen Mehrwert gerechtfertigt sind.
Datensouveränität und Governance
Die Integration von KI in Unternehmensdaten stellt hohe Anforderungen an die Compliance. RAG-Systeme dürfen bestehende Sicherheitsarchitekturen nicht untergraben.
- Berechtigungsmanagement: Das System muss gewährleisten, dass Nutzer via Chat nur Informationen abrufen, für die sie im Quellsystem (z. B. SharePoint) autorisiert sind. Diese Access Control Lists müssen in die Vektordatenbank repliziert und bei jeder Abfrage durchgesetzt werden.
- Compliance & Data Residency: Die Wahl zwischen lokalen Modellen (On-Premise / Private Cloud) und externen Anbietern (z. B. Azure OpenAI) ist primär eine juristische Weichenstellung, die Fragen des Datenschutzes bereits in der Architekturphase final klären muss.
Best-Practices: Use-Cases
Um die architektonischen Unterschiede greifbar zu machen, stellen wir zwei typische Unternehmensanforderungen gegenüber. Hier zeigt sich, warum ein „One Size Fits All“-Ansatz bei RAG nicht zielführend ist.

Use-Case 1: Advanced RAG im technischen Field Service
Das Szenario: Ein Servicetechniker benötigt unter Zeitdruck vor einer stillstehenden Anlage die exakte Spezifikation eines Fehlercodes (z. B. „E-404-X“) sowie die korrespondierende Reparaturanleitung.
Die technische Lösung: Präzision hat hier Priorität. Das System nutzt eine Advanced RAG Pipeline:
- Hybrid Search: Die lexikalische Suche stellt sicher, dass exakt der spezifische Fehlercode gefunden wird, während die Vektorsuche den thematischen Kontext liefert.
- Reranking: Ein nachgelagertes Modell filtert irrelevante Treffer (z. B. Anleitungen veralteter Baureihen) und priorisiert das korrekte Service-Bulletin.
Architektur-Fit: Advanced RAG. Der Fokus liegt auf dem schnellen, halluzinationsfreien Abruf von statischem Wissen aus umfangreichen Dokumentationen. Ein Agent wäre hier unnötig komplex.
Use-Case 2: Agentic RAG mit Tool Use im Order Management
Das Szenario: Ein Kunde fragt im Self-Serviceportal: „Wo bleibt meine Bestellung 12345-6? Falls sie noch nicht versendet ist, bitte die Lieferadresse auf unser Außenlager in München ändern.“
Die technische Lösung: Diese Anfrage erfordert Zugriff auf Echtzeit-Daten und Entscheidungslogik. Ein Agentic RAG System übernimmt die Orchestrierung:
- Decomposition & Tooling: Der Agent identifiziert zwei Teilaufgaben (Status prüfen, Adresse ändern).
- Reasoning Loop:
- Step 1: Statusabruf via ERP-API. Ergebnis: „In Bearbeitung“.
- Logic Check: „Ist Änderung erlaubt? Ja, da Status ≠ Versendet.“
- Step 2: Abruf valider Lieferadressen aus dem CRM (Validierung: Existiert „München“?).
- Step 3: Ausführen der Schreiboperation (Update Address) im ERP-System.
- Step 1: Statusabruf via ERP-API. Ergebnis: „In Bearbeitung“.
- Synthese: Generierung der Antwort inklusive neuer Lieferprognose.
Architektur-Fit: Agentic RAG. Hier geht es nicht nur um Informationswiedergabe, sondern um Aktion. Das System muss dynamische Prozesse abwickeln, Live-Schnittstellen bedienen und mehrstufige Geschäftslogik autonom anwenden.
Roadmap zur Implementierung
- Use-Case Klassifizierung: Analysieren Sie die Problemstellung präzise. Ist eine intelligente Suche ausreichend (Advanced RAG) oder wird ein handelnder Problemlöser benötigt (Agentic RAG)?
- Data & API Audit: Verstehen Sie Ihre Datenstruktur. Für Graph RAG sind z.B. klar definierte Entitäten und Beziehungen notwendig wohingegen für Agentic RAG auch Ihre APIs hohe Relevanz haben.
- Pilotierung: Starten Sie mit Advanced RAG als solider Basis. Sobald Suche und Reranking zuverlässig performen, kann das System modular erweitert werden.
- Integration & Guardrails: Implementieren Sie strikte Zugriffskontrollen und Limits, um Datensicherheit zu gewährleisten.
Fazit
RAG hat sich von einer simplen Sucherweiterung zu einem vielseitigen Architekturbaustein für teilautonome KI-Systeme entwickelt - insbesondere überall dort, wo KI nicht nur antworten, sondern belastbar begründen, nachvollziehbar arbeiten und am Ende handlungsfähige Ergebnisse liefern soll. Der entscheidende Punkt: Nicht jede RAG-Pipeline passt zu jedem Use-Case. Wer „zu klein“ baut, bekommt schwache Qualität – wer „zu groß“ baut, zahlt Komplexität, Betriebskosten und Time-to-Value.
Während Basic RAG bei komplexen Prozessen unzureichend ist, steigert Advanced RAG die Trefferqualität durch Query-Transformation, Hybrid-Search und Reranking signifikant. Graph RAG nutzt Wissensgraphen, um komplexe, verteilte Zusammenhänge aufzulösen und Halluzinationen weiter zu reduzieren. Die Spitze der Entwicklung bildet Agentic RAG: Hier plant das LLM selbstständig, zerlegt Aufgaben und liefert durch iterative Prozesse konkrete, handlungsfähige Ergebnisse.
Unternehmen sind gut beraten, ihre Use-Cases genau zu analysieren und die technologisch passende Stufe zu wählen, statt Trends zu folgen. Sind Sie unsicher, welche RAG-Stufe für Ihr spezifisches Szenario den besten ROI liefert oder wie Sie Ihre Datenbasis optimal vorbereiten?
Wir unterstützen Sie gerne als strategischer Partner bei der Evaluierung Ihrer Use-Cases und der Auswahl der passenden Technologie-Komponenten.